The financial world likes to pretend it is rational. On the chart, there is mathematics. In the report, restrained wording. In the news, “neutral” analysis. And then on Reddit, “unbelievable opportunity,” “everyone is buying” appears — and the market forgets what caution and rationality even mean. In this project, I was not looking at prices, but at words. At how the brain’s cognitive tricks live inside texts: reports, news, and social media.
I collected three layers of financial reality from 2020 to 2025: reports from U.S. public companies (10-K and 10-Q filings from SEC EDGAR), financial news, and large volumes of market-related posts from Twitter and Reddit. Reports are the official stage, where every word passes through lawyers and compliance. News acts like dramaturgy, turning the same numbers into either “record-breaking performance” or “worst decline since 2008.” Social media is the bar where everyone speaks loudly, emotionally, and often with much more confidence than justified. All three describe the same market, but in the language of different cognitive biases.
To make these biases something that could be measured rather than only sensed intuitively, I selected ten key behavioral finance phenomena and translated them into the language of specific lexical patterns. For example, overconfidence in social media often sounds like markers such as “I’m 100% sure,” “guaranteed profit,” “can’t lose,” “no way this goes down,” or “this is a sure thing.” Herd behavior rises to the surface in texts with “everyone is buying,” “we all know,” “join us,” “don’t miss out,” “the whole market is in,” where “we” suddenly knows better than any individual does. Framing in news lives in expressions like “only minor correction” instead of “double-digit drop,” “growth opportunity” instead of “high risk,” or in emphasis on “stability” and “resilience” even when the story is really about contraction.
The list also included anchors — constructions such as “from 52-week high,” “compared to the peak,” “since all-time high,” which create attachment to a certain reference point as the norm. For loss aversion, important phrases included “protect your capital,” “avoid drawdown,” “not willing to lose a single dollar,” “can’t afford any loss.” Information overload appears in texts that stress “too much data,” “endless news flow,” “overwhelmed with information,” “no time to process all reports,” which is directly tied to the way the brain starts economizing on depth of analysis. A separate category was overtrust in algorithms, expressed through phrases like “the bot knows better,” “the model is always right,” “just follow the algo,” “AI already figured it out.”
Next, I needed a measuring stick. Counting individual words means very little if you do not distinguish between a bias that appears rarely but hits at full intensity and one that is spread everywhere as light background noise. For each bias in each channel, I first looked at what share of texts contained characteristic markers, and then at how densely those markers appeared where they were already present. One report with a single mention of “risk” is one thing; dozens of Reddit posts filled with “we all know this will go to the moon” and “just buy, don’t overthink” are something entirely different, even if a simple marker count shows similar numbers.
After running NLP across the full corpus and manually checking part of the fragments, several interesting patterns emerged. Reports turned out to be statistically “full” of biases — they contained markers almost all the time. But when you look at density, the layer is thin. Very thin. There are many instances of “risk,” “uncertainty,” “volatility,” “potential,” but in constructions like “we are subject to market risk,” “there is potential impact of volatility.” This is the language of protection, not the language of panic. That is how the effect I called the “report anomaly” appeared: almost all texts are marked by indicators, but emotional intensity remains low.
Social media shows a different picture. Complex formulas are rare there, but clear-cut judgments are far more common. When the analysis picks up clusters of texts where “guaranteed,” “you can’t lose here,” “everyone is all-in,” “if you miss this, you’ll regret forever,” and “the bot already backtested this strategy” live side by side, the density of overconfidence, herd behavior, and algorithm-trust markers shoots up. This is not background noise, but bursts: on ordinary days the feed may be relatively calm, yet in moments of hype or fear the language shifts sharply — and that shift itself becomes a behavioral signal.
News language is more controlled, but still not neutral. This is where framing does much of its work: “only temporary setback” instead of “significant decline,” “investors take profits” where the reality is mass exit from positions, “strong fundamentals despite short-term volatility” even in situations where the numbers in the table look much less impressive. The study separately highlighted framing subtypes: emphasis on goal achievement (“on track to achieve long-term targets”), avoidance of negatives (“measures to avoid further losses”), positive emphasis (“solid growth,” “resilient performance”), or marketing-style presentation (“exclusive opportunity,” “unique market position”). Together, this creates a stable informational background where a fact never arrives alone — it comes already dressed in the intended mood.
When these three layers are brought together, it becomes obvious how easily a simple model can be deceived. It sees “risk” and “uncertainty” in a report and counts that as bias or fear. It sees a few meme phrases in a thread and may simply blend them into everything else. Without context, a report looks just as “emotional” as a wave of FOMO. Even though in one case we are reading legal armor, and in the other, collective certainty that “it is impossible to be wrong here.” A question for you. Do you also use AI models to “read the market” faster — to scan reports, extract insights from news and social media? That is normal; it is 2026 after all. But there is a catch. An algorithm that cannot distinguish genre, hear irony, or detect cognitive patterns in language becomes just another participant in herd behavior. Only without the habit of doubt. It catches a single word and immediately concludes something about “market sentiment,” without asking itself: is this a signal that “we are all running,” or just another paragraph in the Risk Factors section of a 10-K?
These models extract texts, build “fear,” “greed,” and “optimism” indices, highlight things in red and green, and suggest where to click. If their view of language is flat, they repeat the same cognitive mistakes humans make — only faster. The algorithm does not get tired or anxious, but it also does not ask itself, “Is this really a shift in sentiment, or just the style of the document?” This is exactly where an additional layer is needed — one that distinguishes genre, context, and behavioral patterns, rather than merely counting words.
How can you use this?
For FinTech teams and banks, this is about system architecture. It is important to teach models to distinguish the language of compliance in reports from the language of behavioral flare-ups in social media and news. Dictionary-style indicators are most useful where language is “alive” — in news texts and discussions — as early detectors of herd waves and overconfidence. For reports, they are better combined with contextual models such as FinBERT or specially trained LLMs, plus mandatory qualitative review. This way, on top of standard text metrics, separate profiles of herding, framing, and trust in algorithms can be built across channels without penalizing a company simply for honestly complying with regulatory requirements.
For financial analysts and investors, this work is a reminder that numbers always arrive together with language, and language carries its own stable distortions. Reports should not be treated as a “clean signal” when they use standard formulations about uncertainty and risk — these are often more about legal self-protection. News is better read with the question, “What frame are these numbers being placed into right now?” And social media should be viewed as a map of places where rhetoric has shifted into “everyone is sure it is impossible to be wrong,” which is itself a signal for caution.
For people who use financial apps and invest from time to time, this is a chance to add one more filter to their internal financial hygiene: how exactly someone is speaking to you. A report that repeats “uncertainty” many times does not automatically mean everything will collapse tomorrow. A news story with “historic rally” may describe a move that looks like ordinary volatility on the chart. A thread full of confident voices about easy profit may be not a revelation of “collective intelligence,” but a textbook example of Overconfidence, Herd Behavior, and AI Overtrust packed into one set of phrases.
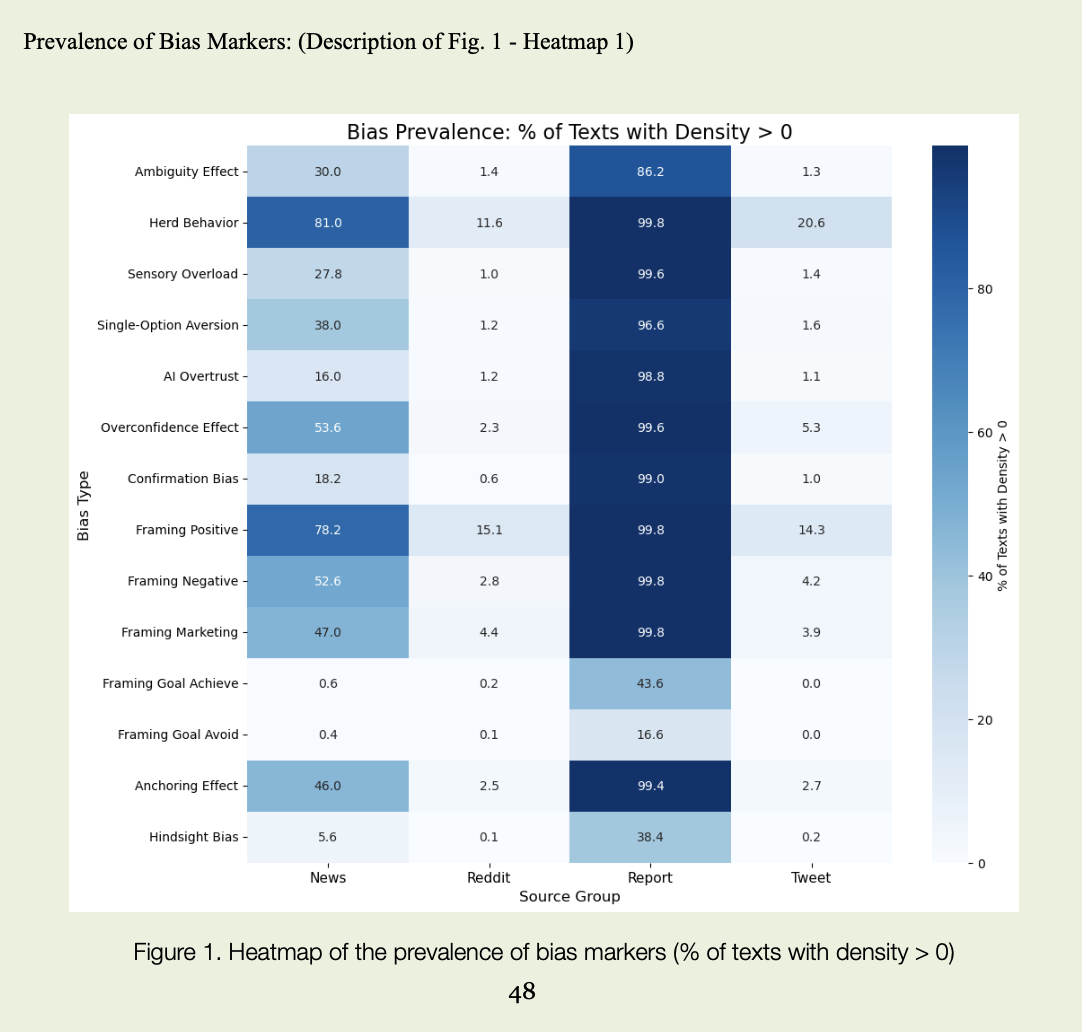
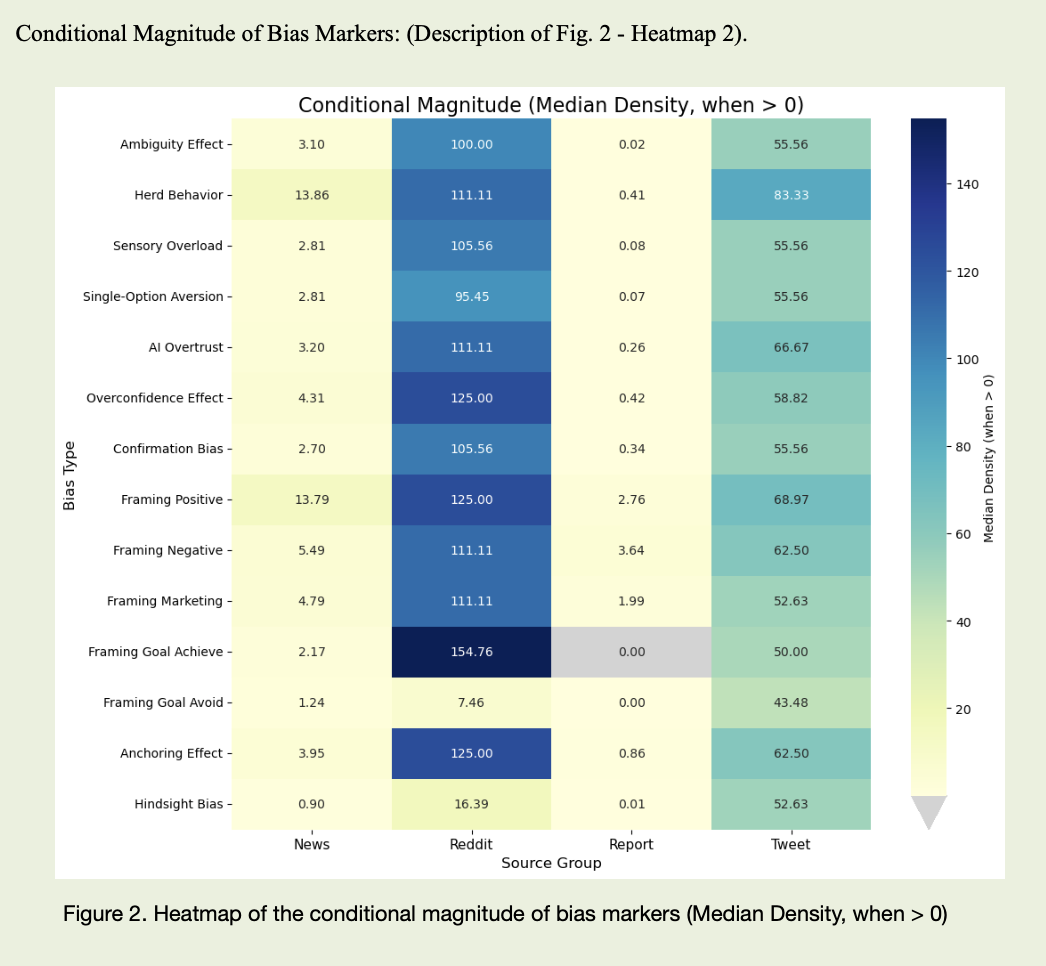
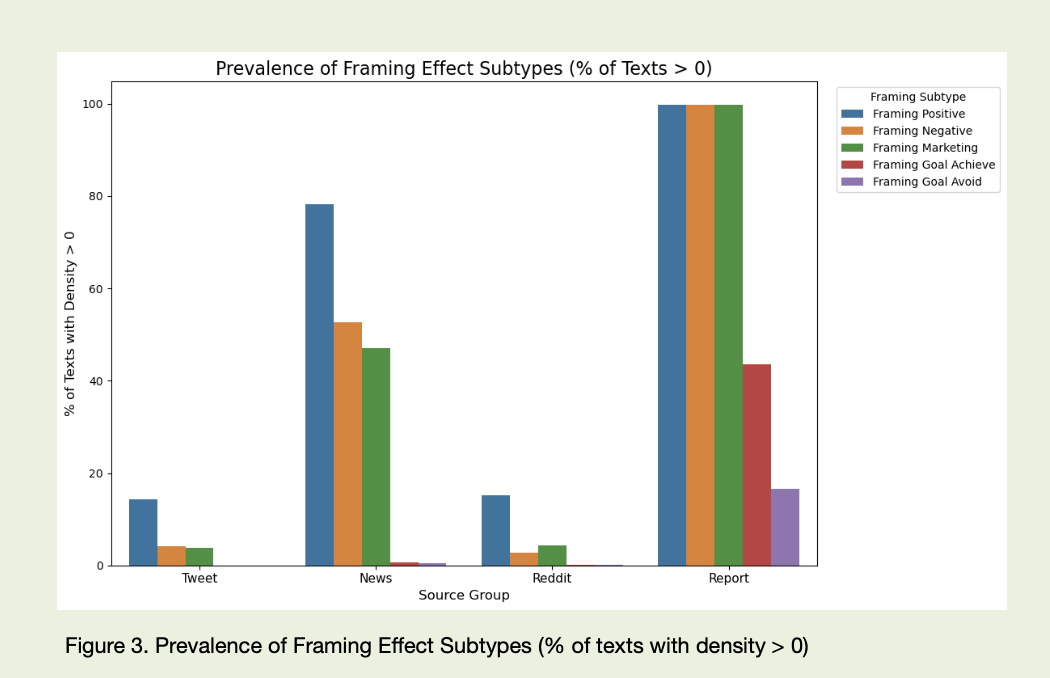
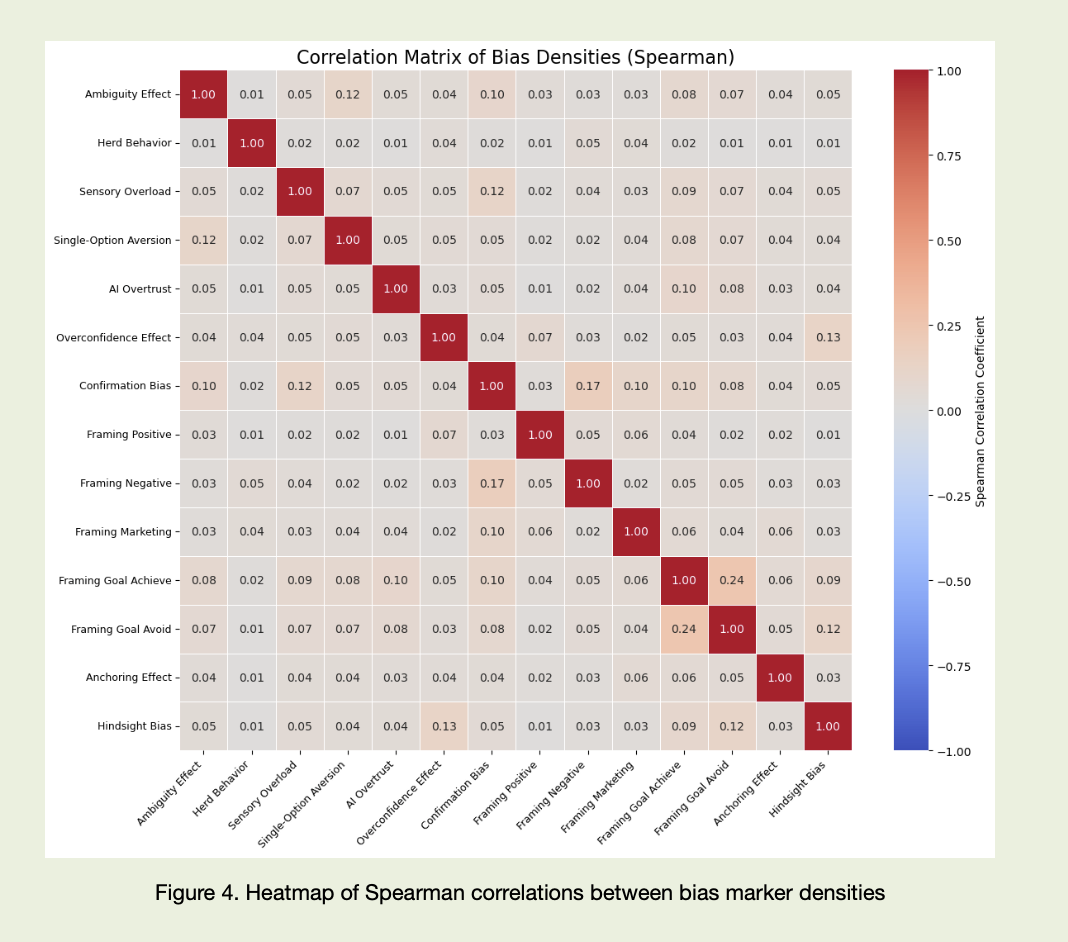
In the end, this case is about language. And about the brain. And about how they interact with money. About the way cognitive patterns are embedded in texts and move markets no less than macro data does. And about the fact that in 2026, the winner is not the one who has more information, but the one who sees more clearly through which lenses that information reaches them — and their models.