Фінансовий світ любить прикидатися раціональним. На графіку — математика. У звіті — стримані формулювання. У новинах — «нейтральний» аналіз. А потім на Reddit з’являється «unbelievable opportunity», «everyone is buying» — і ринок забуває, що таке обережність та раціональність. У цьому проєкті я дивилась не на ціни, а на слова. На те, як когнітивні трюки мозку живуть у текстах: звітах, новинах, соцмережах.
Я зібрала три шари фінансової реальності за 2020–2025 роки: звіти публічних компаній США (10-K і 10-Q із SEC EDGAR), фінансові новини та великі масиви постів із Twitter і Reddit, присвячені ринку. Звіти — офіційна сцена, де кожне слово проходить через юристів і комплаєнс. Новини — драматурги, які з одних і тих самих чисел роблять або «record-breaking performance», або «worst decline since 2008». Соцмережі — бар, де всі говорять голосно, емоційно і часто впевнені у собі значно більше, ніж це виправдано. Усі троє описують той самий ринок, але мовою різних когнітивних упереджень.
Щоб ці упередження можна було не тільки відчувати інтуїтивно, а й вимірювати, я вибрала десять ключових феноменів поведінкових фінансів і перевела їх на мову конкретних лексичних патернів. Наприклад, завищена впевненість у соцмережах часто звучить через маркери типу «I’m 100% sure», «guaranteed profit», «can’t lose», «no way this goes down», «this is a sure thing». Стадна поведінка виходить на поверхню в текстах із «everyone is buying», «we all know», «join us», «don’t miss out», «the whole market is in», де «ми» раптом знає краще за всіх окремо. Рамкування в новинах живе у формулюваннях «only minor correction» замість «double-digit drop», «growth opportunity» замість «high risk», або в акцентах на «stability» і «resilience» навіть там, де йдеться про скорочення.
До списку увійшли також якорі — такі конструкції, як «from 52-week high», «compared to the peak», «since all-time high», які створюють прив’язку до певної точки як норми. Для уникнення втрат важливі вирази на кшталт «protect your capital», «avoid drawdown», «not willing to lose a single dollar», «can’t afford any loss». Інформаційне перевантаження виявляється в текстах, де підкреслюється «too much data», «endless news flow», «overwhelmed with information», «no time to process all reports», що напряму пов’язано з тим, як мозок починає економити на глибині аналізу. Окрема категорія — надмірна довіра до алгоритмів, яка звучить як «the bot knows better», «the model is always right», «just follow the algo», «AI already figured it out».
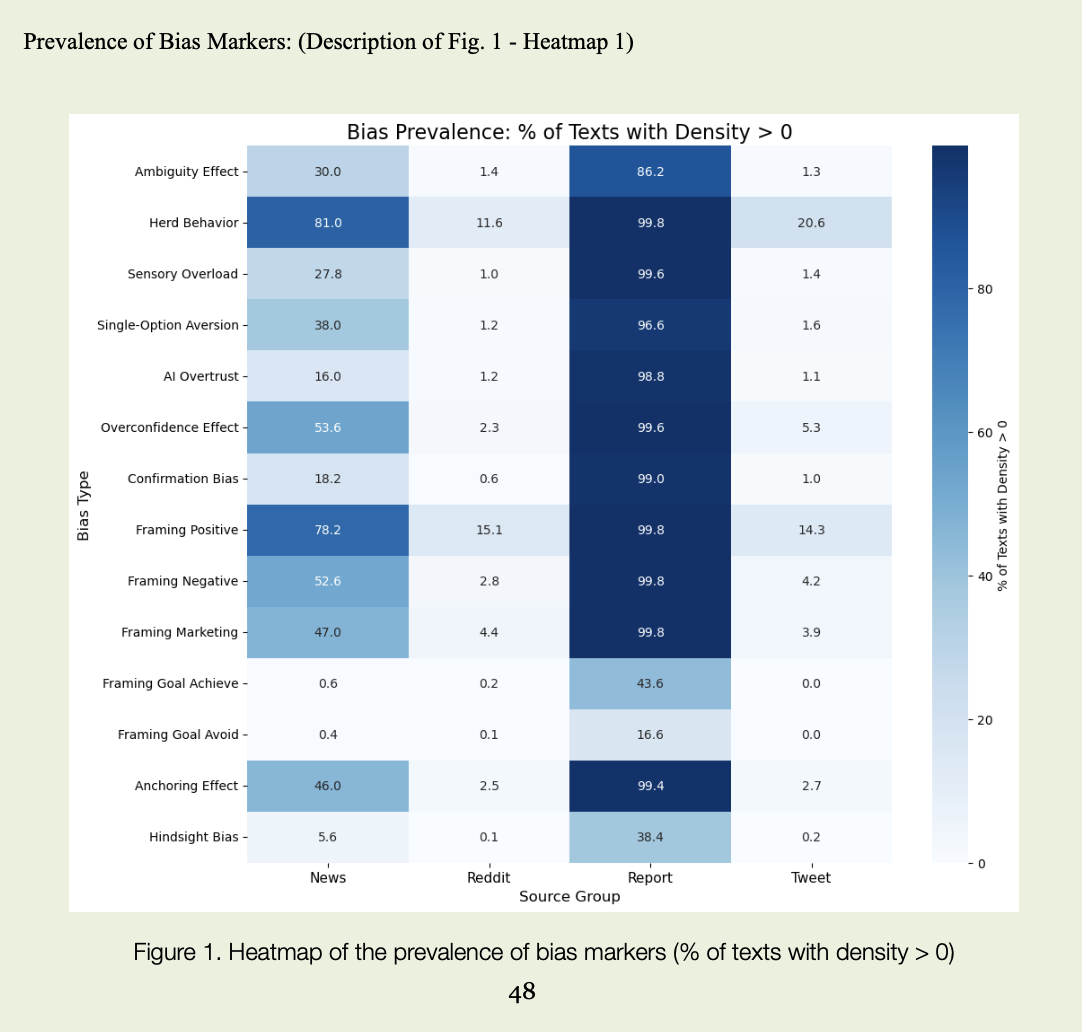
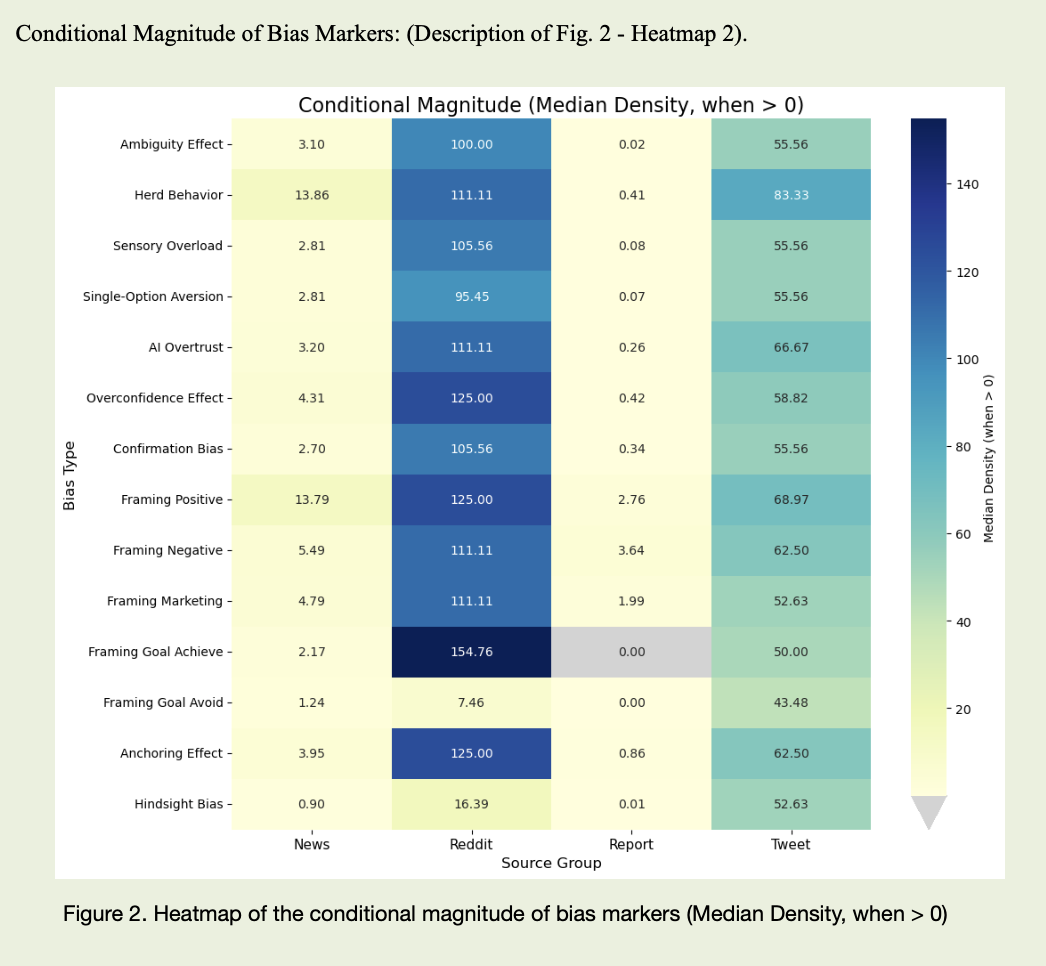
Далі потрібно було навісити на це лінійку. Підрахунок окремих слів нічого не дає, якщо не розрізняти, де упередження зустрічається рідко, але «б’є по максимуму», а де присутнє всюди легким шумом. Для кожного упередження у кожному каналі я дивилася спершу на те, в якій частці текстів з’являються характерні маркери, а потім — наскільки щільно вони присутні там, де вже є. Один звіт із поодинокою згадкою «risk» — це одне, а десятки Reddit-постів із «we all know this will go to the moon» і «just buy, don’t overthink» — щось зовсім інше, навіть якщо лічильник «кількість маркерів» показує схожі цифри.
Після NLP-проходу по всьому корпусу й ручної перевірки частини фрагментів вилізло кілька цікавих сюжетів. Звіти виявилися «переповнені» упередженнями за статистикою — вони містили маркери майже завжди. Та коли дивишся на щільність, там тонкий шар. Дуже тонкий. Багато «risk», «uncertainty», «volatility», «potential», але в конструкціях типу «we are subject to market risk», «there is potential impact of volatility». Це мова захисту, а не мова паніки. Так з’явився ефект, який я для себе назвала «аномалією звітів»: майже всі тексти позначені маркерами, але емоційної інтенсивності там мало.
У соцмережах картина інша. Там рідко зустрічаються складні формули, але набагато частіше — однозначні судження. Коли аналіз фіксує кластери текстів, де поруч живуть «guaranteed», «you can’t lose here», «everyone is all-in», «if you miss this, you’ll regret forever», «the bot already backtested this strategy», щільність маркерів завищеної впевненості, стадної поведінки й довіри до алгоритмів злітає вгору. Це не фон, а спалахи: у звичайні дні стрічка може бути відносно спокійною, зате у моменти хайпу чи страху мова різко змінюється, й саме це стає поведінковим сигналом.
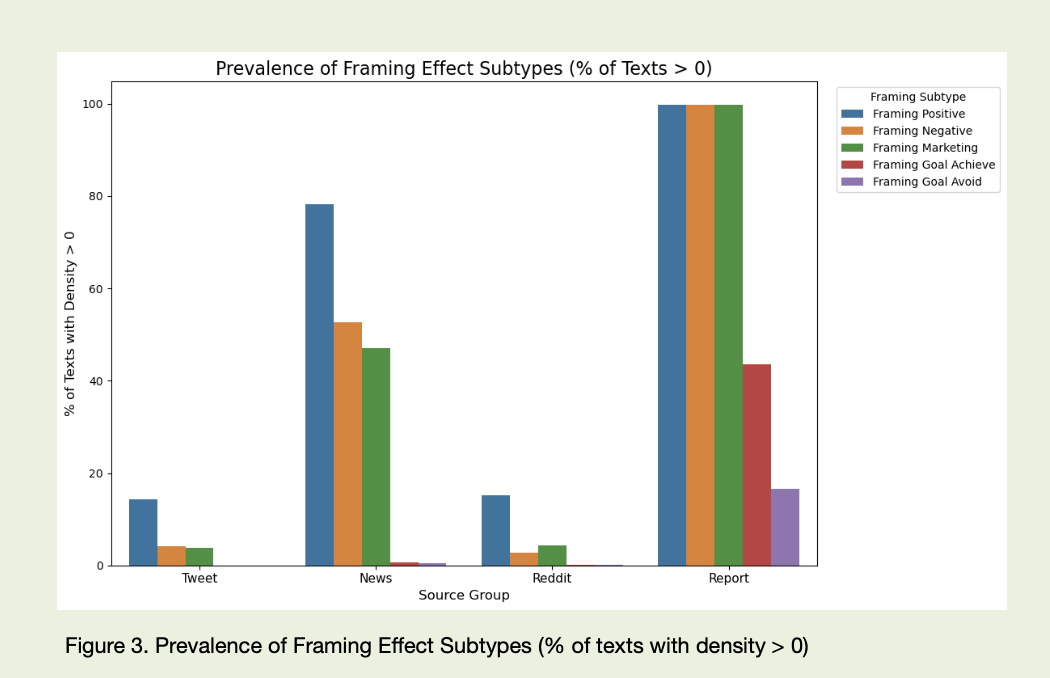
У новинах мова більш керована, але теж не нейтральна. Тут часто грають рамками: «only temporary setback» замість «значне падіння», «investors take profits» там, де по факту фіксуються масові виходи з позицій, «strong fundamentals despite short-term volatility» навіть у ситуаціях, де числа в таблиці виглядають значно скромніше. У роботі окремо виділялися підтипи рамкування: коли акцент робиться на досягненні цілей («on track to achieve long-term targets»), уникненні негативу («measures to avoid further losses»), підкресленні позитиву («solid growth», «resilient performance») або маркетинговій подачі («exclusive opportunity», «unique market position»). Сукупно це створює стійке інформаційне тло, де факт ніколи не приходить сам — він одразу одягнений у потрібний настрій.
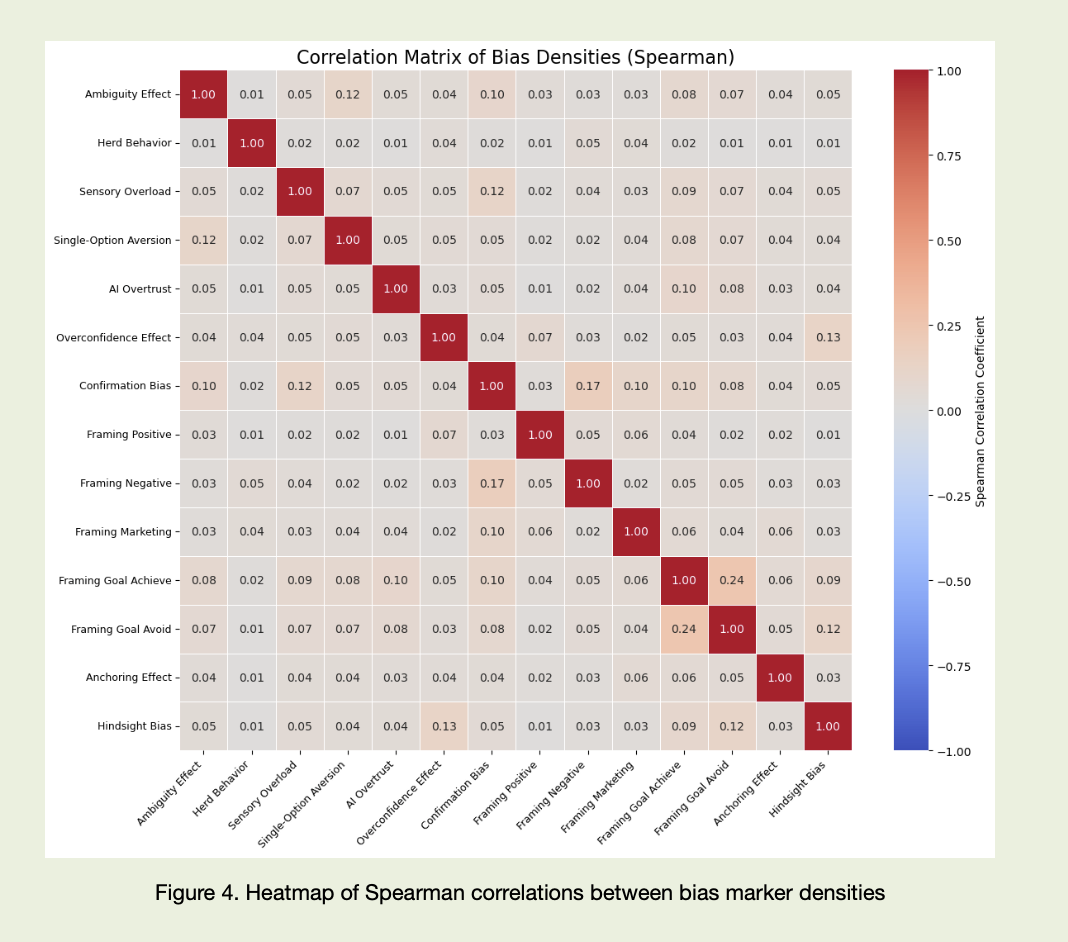
Коли звести ці три шари разом, стає видно, як легко обдурюється проста модель. Вона бачить «risk», «uncertainty» у звіті й рахує це як упередженість або страх. Вона бачить кілька мемних фраз у треді й, можливо, сумує їх із усім іншим. Без контексту звіт виглядає таким самим «емоційним», як хвиля FOMO. Хоча в одному випадку ми читаємо юридичну броню, в іншому — колективну впевненість, що «тут неможливо помилитися». Питання до вас. Ви теж користуєтеся AI-моделями, щоб швидше «прочитати ринок» — пробігтись по звітах, витягнути інсайти з новин і соцмереж? Це нормально, 2026 рік усе-таки. Але є нюанс. Алгоритм, який не відрізняє жанр, не чує іронії й не бачить когнітивних патернів мови, стає ще одним учасником стадної поведінки. Тільки без звички сумніватися. Він ловить окреме слово й одразу робить висновок про «настрій ринку», не запитуючи себе: це сигнал «ми всі біжимо», чи черговий абзац у розділі Risk factors у 10-K.
Такі моделі витягують тексти, будують індекси «страху», «жадібності», «оптимізму», підсвічують червоним і зеленим, радять, куди натиснути. Якщо їхнє бачення мови плоске, вони повторюють ті самі когнітивні помилки, які робить людина, лише швидше. Алгоритм не втомлюється й не нервує, але й не ставить собі запитання «це справді зміна настрою чи просто стиль документа?». Саме тут потрібен додатковий шар — те, що розрізняє жанр, контекст і поведінкові патерни, а не лише рахує слова.
Як це використати вам?
Для FinTech-команд і банків це про архітектуру систем. Важливо навчити моделі відрізняти мову комплаєнсу у звітах від мови поведінкових спалахів у соцмережах і новинах. Словникові індикатори доцільно застосовувати там, де мова «жива» — у новинних текстах та обговореннях — як ранній детектор хвиль стадної поведінки та завищеної впевненості. Для звітів їх краще поєднувати з контекстними моделями на кшталт FinBERT або спеціально навченими LLM плюс обов’язковою якісною перевіркою. Тоді поверх звичайних метрик тексту можна будувати окремі профілі стадності, рамкування, довіри до алгоритмів у різних каналах, не караючи компанію тільки за те, що вона чесно виконує вимоги регулятора.
Для фінансових аналітиків та інвесторів ця робота нагадує, що цифри завжди приходять разом із мовою, а мова має свій набір стабільних зсувів. Звіти не варто сприймати як «чистий сигнал», якщо в них використано стандартні формули про невизначеність і ризики — вони часто більше про юридичний самозахист. Новини краще читати з питанням «у яку рамку мені зараз вкладають ці числа?». А соцмережі — розглядати як карту місць, де риторика перейшла в режим «усі впевнені, що помилитися неможливо», що саме по собі є сигналом обережності.
Для людей, які користуються фінансовими застосунками й періодично інвестують, це можливість додати до своєї внутрішньої фінансової гігієни ще один фільтр: як саме з вами говорять. Звіт, який багато разів повторює «uncertainty», ще не означає, що завтра все впаде. Новина з «historic rally» може описувати рух, який на графіку виглядає як звичайна волатильність. Тред із десятка впевнених voices про легкий прибуток може бути не прозрінням «колективного розуму», а зразковим прикладом поєднання Overconfidence, Herd Behavior і AI Overtrust у одному наборі фраз.
У підсумку цей кейс про мову. І про мозок. І про те, як вони взаємодіють із грошима. Про те, як у текстах зашиті когнітивні патерни, які рухають ринок не менше, ніж макродані. І про те, що в 2026 році виграє не той, у кого більше інформації, а той, хто краще бачить, через які лінзи ця інформація проходить до нього — і до його моделей.