El mundo financiero adora fingir que es racional. En el gráfico, hay matemáticas. En el informe, fórmulas contenidas. En las noticias, análisis “neutral”. Y luego en Reddit aparecen “unbelievable opportunity”, “everyone is buying”, y el mercado se olvida de qué eran la prudencia y la racionalidad. En este proyecto no miré los precios, sino las palabras. Cómo los trucos cognitivos del cerebro viven dentro de los textos: informes, noticias y redes sociales.
Reuní tres capas de realidad financiera de 2020 a 2025: informes de empresas cotizadas de EE. UU. (10‑K y 10‑Q del SEC EDGAR), noticias financieras y grandes volúmenes de posts en Twitter y Reddit dedicados al mercado. Los informes son el escenario oficial, donde cada palabra pasa por abogados y compliance. Las noticias son los dramaturgos que con los mismos números construyen “record‑breaking performance” o “worst decline since 2008”. Las redes sociales son el bar donde todos hablan alto, emocionalmente y muchas veces con más confianza de la que está justificada. Los tres describen el mismo mercado, pero en el lenguaje de sesgos cognitivos distintos.
Para que estos sesgos fueran algo que se pueda medir y no solo intuir, seleccioné diez fenómenos clave de las finanzas conductuales y los traduje al lenguaje de patrones léxicos concretos. Por ejemplo, la sobreconfianza en redes sociales suele sonar a marcadores como “I’m 100% sure”, “guaranteed profit”, “can’t lose”, “no way this goes down”, “this is a sure thing”. El comportamiento de manada aparece en textos con “everyone is buying”, “we all know”, “join us”, “don’t miss out”, “the whole market is in”, donde ese “nosotros” de repente sabe más que cualquiera por separado. El encuadre en las noticias vive en expresiones como “only minor correction” en lugar de “double-digit drop”, “growth opportunity” en vez de “high risk”, o en el énfasis en “stability” y “resilience” incluso cuando el contenido real es de recortes.
La lista también incluía anclas: construcciones como “from 52-week high”, “compared to the peak”, “since all-time high”, que fijan una referencia como norma. Para la aversión a la pérdida, eran importantes frases como “protect your capital”, “avoid drawdown”, “not willing to lose a single dollar”, “can’t afford any loss”. La sobrecarga informativa aparece en textos que subrayan “too much data”, “endless news flow”, “overwhelmed with information”, “no time to process all reports”, lo que se relaciona directamente con cómo el cerebro empieza a ahorrar en profundidad de análisis. Una categoría aparte era la confianza excesiva en los algoritmos, que suena como “the bot knows better”, “the model is always right”, “just follow the algo”, “AI already figured it out”.
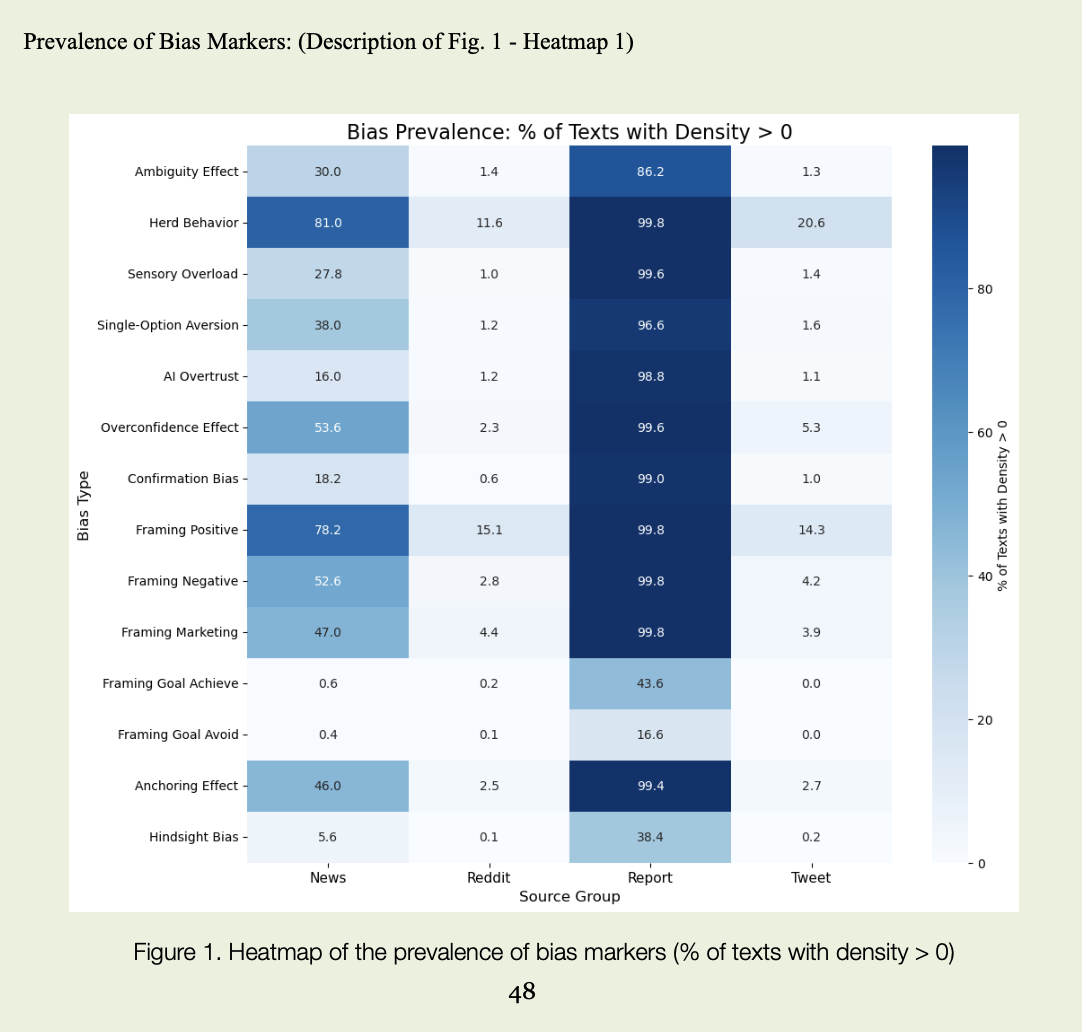
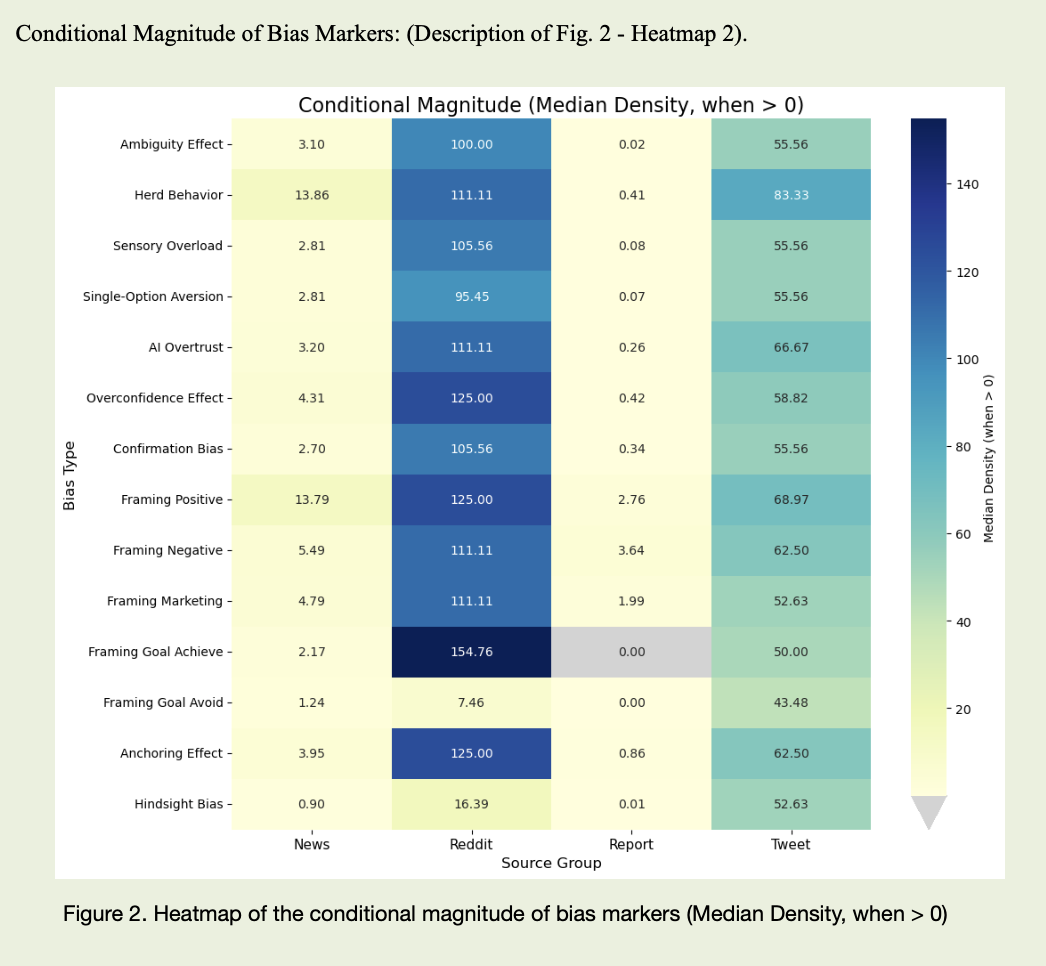
Después hacía falta poner una regla. Contar palabras sueltas no dice gran cosa si no distingues dónde el sesgo aparece pocas veces, pero con máxima intensidad, y dónde está presente en todas partes como un ruido ligero de fondo. Para cada sesgo en cada canal miraba primero qué proporción de textos contenía marcadores característicos, y luego qué tan densos eran allí donde ya aparecían. Un informe con una única mención de “risk” es una cosa; decenas de posts en Reddit llenos de “we all know this will go to the moon” y “just buy, don’t overthink” son algo muy distinto, incluso si el simple recuento de marcadores da cifras parecidas.
Tras pasar todo el corpus por NLP y revisar manualmente una parte de los fragmentos, salieron varios guiones interesantes. Los informes resultaron “llenos” de sesgos según las estadísticas — casi siempre contienen marcadores. Pero cuando miras la densidad, la capa es fina. Muy fina. Hay muchos “risk”, “uncertainty”, “volatility”, “potential”, pero en construcciones como “we are subject to market risk”, “there is potential impact of volatility”. Es un lenguaje de protección, no de pánico. De ahí salió el efecto que internamente llamé “anomalía de los informes”: casi todos los textos están marcados, pero la intensidad emocional es baja.
En redes sociales el cuadro es distinto. Allí rara vez aparecen fórmulas complejas, pero son mucho más frecuentes los juicios categóricos. Cuando el análisis detecta clusters de textos donde viven juntos “guaranteed”, “you can’t lose here”, “everyone is all-in”, “if you miss this, you’ll regret forever”, “the bot already backtested this strategy”, la densidad de marcadores de sobreconfianza, comportamiento de manada y confianza en algoritmos se dispara. No es ruido de fondo, sino destellos: en días normales el feed puede ser relativamente tranquilo; en momentos de hype o miedo, el lenguaje cambia bruscamente, y ese cambio se convierte en señal conductual.
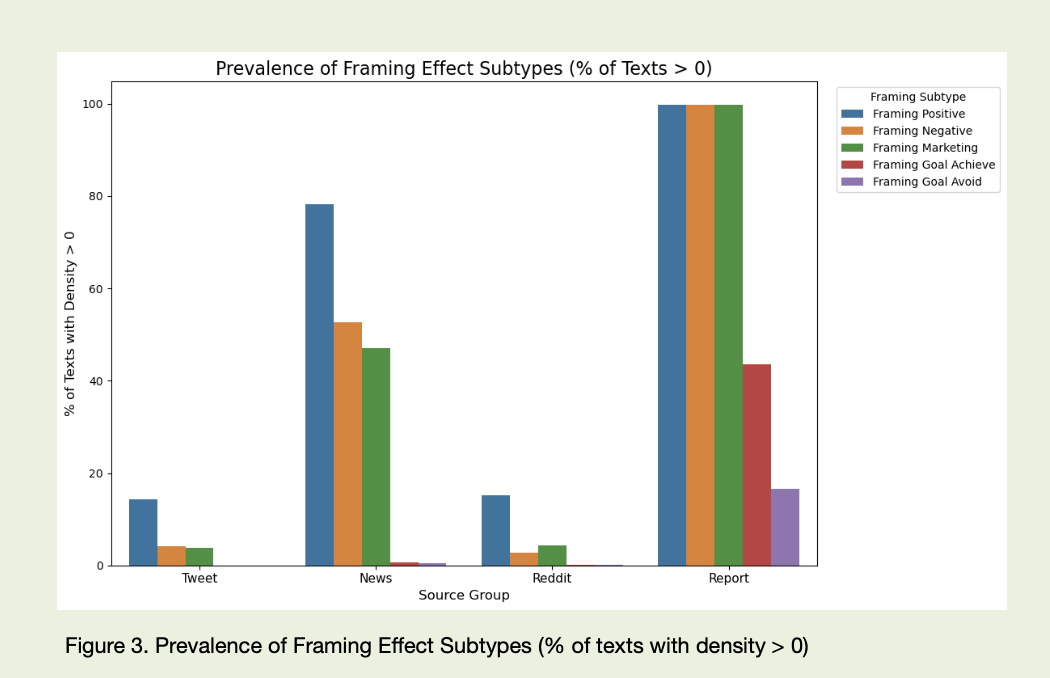
El lenguaje de las noticias está más controlado, pero tampoco es neutro. Es donde el encuadre hace gran parte del trabajo: “only temporary setback” en vez de “significant decline”, “investors take profits” donde en realidad hay salidas masivas de posiciones, “strong fundamentals despite short-term volatility” incluso en situaciones en las que las cifras de la tabla se ven mucho más discretas. El estudio destacó subtipos de encuadre: cuando el foco se pone en el logro de objetivos (“on track to achieve long-term targets”), en evitar lo negativo (“measures to avoid further losses”), en enfatizar lo positivo (“solid growth”, “resilient performance”) o en una presentación de estilo marketing (“exclusive opportunity”, “unique market position”). En conjunto, esto crea un fondo informativo estable donde el hecho nunca llega solo: viene ya vestido con el estado de ánimo deseado.
Al colocar estas tres capas una al lado de la otra, se ve con claridad lo fácil que es engañar a un modelo simple. Ve “risk” y “uncertainty” en un informe y lo cuenta como sesgo o miedo. Ve unas cuantas frases‑meme en un hilo y puede mezclarlas con todo lo demás. Sin contexto, un informe puede parecer tan “emocional” como una ola de FOMO. Aunque en un caso estamos leyendo una armadura legal, y en el otro, una certeza colectiva de que “aquí es imposible equivocarse”. Pregunta para ti. ¿También usas modelos de IA para “leer el mercado” más rápido — escanear informes, sacar insights de noticias y redes sociales? Es normal, estamos en 2026. Pero hay un matiz. Un algoritmo que no distingue género, no escucha ironía y no ve patrones cognitivos en el lenguaje se convierte en un participante más del comportamiento de manada. Solo que sin el hábito de dudar. Atrapa una palabra suelta y enseguida concluye algo sobre el “sentimiento del mercado”, sin preguntarse: ¿es una señal de que “todos corremos”, o simplemente un párrafo más en la sección de Risk Factors de un 10‑K?
Estos modelos extraen textos, construyen índices de “miedo”, “codicia”, “optimismo”, colorean en rojo y verde y sugieren dónde hacer clic. Si su visión del lenguaje es plana, repiten los mismos errores cognitivos que comete una persona, solo que más rápido. El algoritmo no se cansa ni se pone nervioso, pero tampoco se pregunta “¿esto es realmente un cambio de ánimo o solo el estilo del documento?”. Ahí es donde hace falta una capa adicional: algo que distinga género, contexto y patrones de conducta, y no solo cuente palabras.
¿Cómo puedes usarlo tú?
Para equipos FinTech y bancos, esto va de arquitectura de sistemas. Es clave enseñar a los modelos a distinguir el lenguaje de compliance en informes del lenguaje de estallidos conductuales en redes y noticias. Los indicadores léxicos tienen más sentido allí donde el lenguaje está “vivo” — en textos de actualidad y debates — como detectores tempranos de olas de comportamiento de manada y sobreconfianza. En informes, conviene combinarlos con modelos contextuales como FinBERT o LLM entrenados específicamente, más una revisión cualitativa obligatoria. Así, además de las métricas textuales estándar, se pueden construir perfiles separados de manada, encuadre y confianza en algoritmos en distintos canales, sin penalizar a una empresa solo por cumplir honestamente las exigencias del regulador.
Para analistas financieros e inversores, este trabajo recuerda que los números siempre vienen acompañados de lenguaje, y que el lenguaje trae sus propias distorsiones estables. No tiene sentido tratar los informes como “señal limpia” cuando usan fórmulas estándar sobre incertidumbre y riesgo: muchas veces hablan más de autoprotección legal que del estado real del negocio. Las noticias es mejor leerlas preguntando “¿en qué marco están colocando ahora estos números?”. Y las redes sociales conviene mirarlas como un mapa de lugares donde la retórica ha pasado a “todo el mundo está seguro de que es imposible equivocarse”, lo cual ya es una señal de prudencia.
Para personas que usan apps financieras e invierten de vez en cuando, esto es una oportunidad de añadir otro filtro a su higiene financiera interna: cómo te hablan. Un informe que repite muchas veces “uncertainty” no significa automáticamente que todo vaya a hundirse mañana. Una noticia con “historic rally” puede describir un movimiento que en el gráfico parece volatilidad habitual. Un hilo lleno de voces muy seguras sobre beneficios fáciles puede no ser una revelación del “inteligencia colectiva”, sino un ejemplo de manual de Overconfidence, Herd Behavior y AI Overtrust en un mismo conjunto de frases.
En el fondo, este caso va de lenguaje. Y del cerebro. Y de cómo interactúan con el dinero. De cómo los patrones cognitivos están incrustados en los textos y mueven los mercados tanto como los datos macro. Y de que en 2026 no gana quien tiene más información, sino quien ve mejor a través de qué lentes llega esa información a él — y a sus modelos.